| Location | Date |
|---|---|
| Berkeley's NLP Seminar | 14.07.21 |
| MIT's Computational Psycholinguistics Lab | 16.06.21 |
Abstract
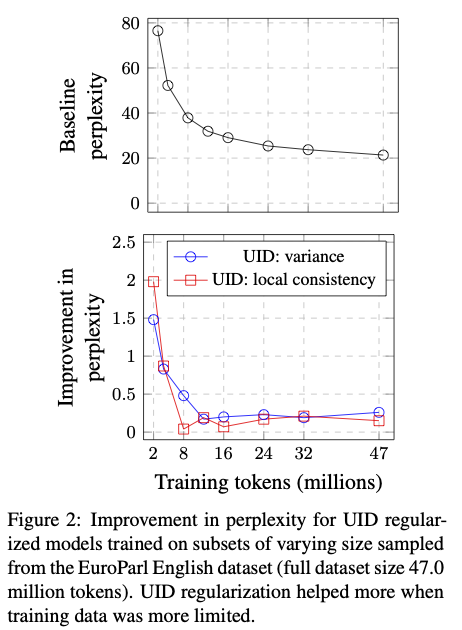
In this talk, I will review two recent works that have operationalized the uniform information density (UID) hypothesis for use in models of natural language processing. In machine translation, it has been frequently observed that texts assigned high probability (i.e., low surprisal) are not necessarily what humans perceive to be high quality language. Alternatively, text decoded using beam search, a popular heuristic decoding method, often scores well in terms of both qualitative and automatic evaluation metrics, such as BLEU. We show that beam search can be framed as a UID-enforcing decoding objective and that there exists a strong relationship between BLEU and the extent to which UID is adhered to in natural language text. In a follow up work, we explore the effects of directly incorporating an operationalization of UID into a language model’s training objective. Specifically, we augment the canonical MLE objective with a regularizer that encodes UID. In experiments on ten languages spanning five language families, we find that using UID regularization consistently improves perplexity in language models, having a larger effect when training data is limited. Moreover, via an analysis of generated sequences, we find that UID-regularized language models have other desirable properties, e.g., they generate text that is more lexically diverse.